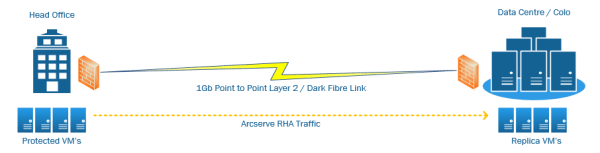
Arcserve RHA (Replication & High Availability) is one of the core products within the Arcserve suite. At a glance, the Arceserve solution is made up of 3 key components: Arcserve Backup - Tape Backups Arcserve UDP / D2D - Disk to Disk Arcserve RHA - Replication & High Availability Having years of experience operating &... Continue Reading →
Arcserve RHA Reverse Scenario (Failback) Considerations & Preperation